HAWQ是什么?
HAWQ是一个Hadoop原生SQL查询引擎,它结合了MPP数据库的关键技术优势和Hadoop的可扩展性和方便性。
HAWQ从HDFS本地读取数据并将数据写入HDFS。
HAWQ提供业界领先的性能和线性可扩展性。
它为用户提供了简单和成功地与PB级数据集交互的工具。
HAWQ为用户提供了一个完整的、符合标准的SQL接口。
更具体地说,HAWQ具有以下特点:
- 内部部署或云部署
- 健壮的ANSI SQL遵从性:SQL-92、SQL-99、SQL-2003、OLAP扩展
- 极高的性能—比其他Hadoop SQL引擎快很多倍
- 世界级并行优化器
- 完整的事务处理能力和一致性保证:ACID
- 基于高速UDP互连的动态数据流引擎
- 基于按需的virtual segments 和 data locality的弹性执行引擎
- 支持多级分区和基于 List/Range的分区表。
- 支持多种压缩方法:snappy、gzip
- 多语言用户自定义函数支持:Python、Perl、java、C/C++、R
- 通过MADLib实现高级机器学习和数据挖掘功能
- 动态节点扩展:秒
- 最先进的三级资源管理:与YARN和分层资源队列集成。
- 轻松访问所有HDFS数据和外部系统数据(例如,HBase)
- Hadoop原生:从存储(HDFS)、资源管理(YARN)到部署(Ambari)。
- 身份验证和细粒度授权:Kerberos、SSL和基于角色的访问
- 先进的C/C++访问库:HDBFS和YARN: libhdfs3 和libYARN
- 支持大多数第三方工具:Tableau、SAS等。
- 标准连接:JDBC/ODBC
HAWQ将复杂的查询分解为小任务,并将它们分发给MPP查询处理单元执行。
HAWQ的基本并行单元是segment实例。
商品服务器上的多个segment实例协同工作,形成一个单一的并行查询处理系统。
提交给HAWQ的查询经过优化,分解成更小的组件,并分派到segments上一起工作,每个segment返回单个结果集的各个部分。
所有关系操作(如table scans、joins、aggregations和sorts)都会同时跨segments并行执行。
动态管道中来自上游组件的数据通过User Datagram Protocol(UDP)互连传输到下游组件。
HAWQ基于Hadoop的分布式存储,无单点故障,支持全自动在线恢复。
系统状态被持续监视,因此如果某个segmemt出现故障,它将自动从集群中删除。
在此过程中,系统将继续为客户查询提供服务,必要时可以将这些segments添加回系统。
HAWQ是什么?
HAWQ 架构
表分配和存储
弹性查询执行运行时间
资源管理
HDFS Catalog 缓存
HAWQ管理工具
高可用性、冗余性和故障容错
HAWQ 架构
in this topic:
ii.HAWQ Segment
vi.HAWQ Fault Tolerance Service
vii.HAWQ Dispatcher
本主题介绍HAWQ体系结构及其主要组件。
在典型的HAWQ部署中,每个slave节点都安装了一个物理HAWQ segment、一个HDFS DataNode和一个NodeManager。
HAWQ、HDFS和YARN的master部署在不同的节点上。
下图提供了典型HAWQ部署的高级体系结构视图。
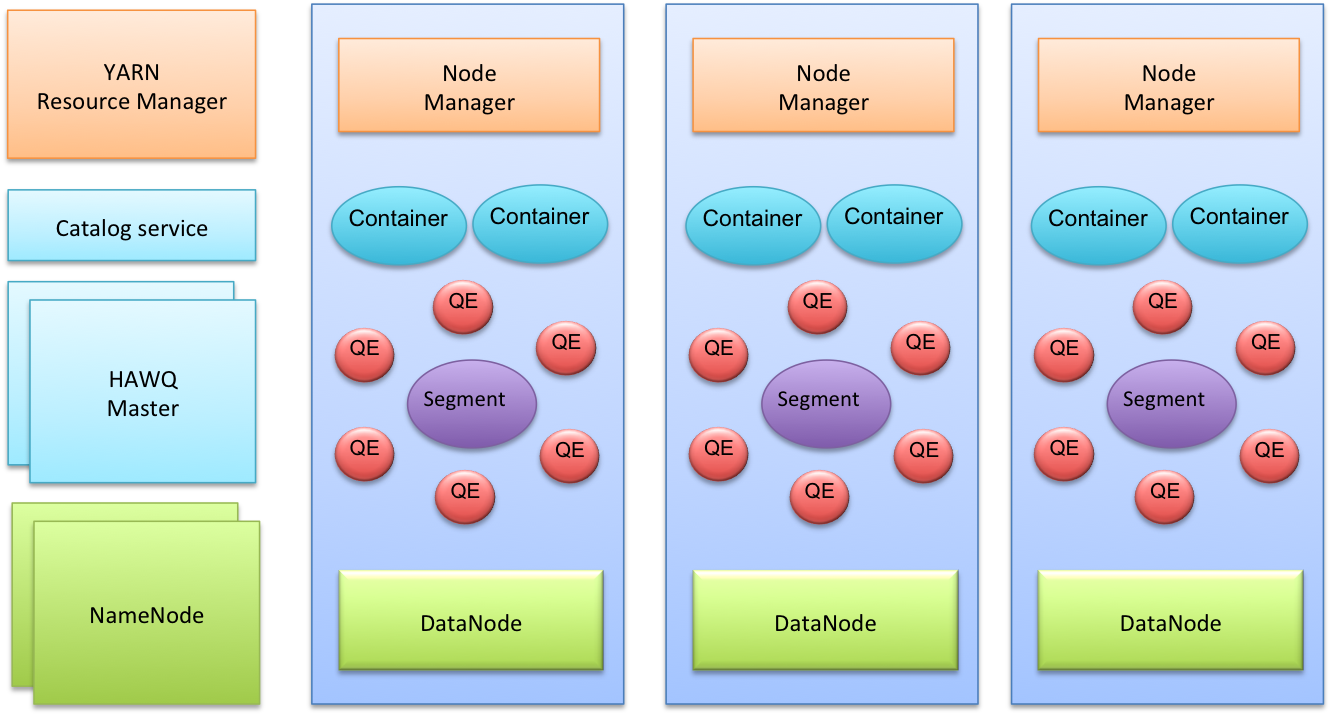
HAWQ与YARN(Hadoop资源管理框架)紧密集成,用于查询资源管理。
HAWQ将YARN中的容器缓存在资源池中,然后通过利用HAWQ自己针对用户和组的更细粒度的资源管理在本地管理这些资源。
为了执行查询,HAWQ根据查询的成本,资源队列定义,数据位置和系统中当前的资源使用情况分配一组virtual segments。
然后将查询分派到相应的物理主机,这些物理主机可以是集群的子集或整个群集。
每个节点上的HAWQ资源强制执行监视和控制查询所使用的实时资源,以避免违反资源使用情况。
下图提供了构成HAWQ的软件组件的另一个视图。
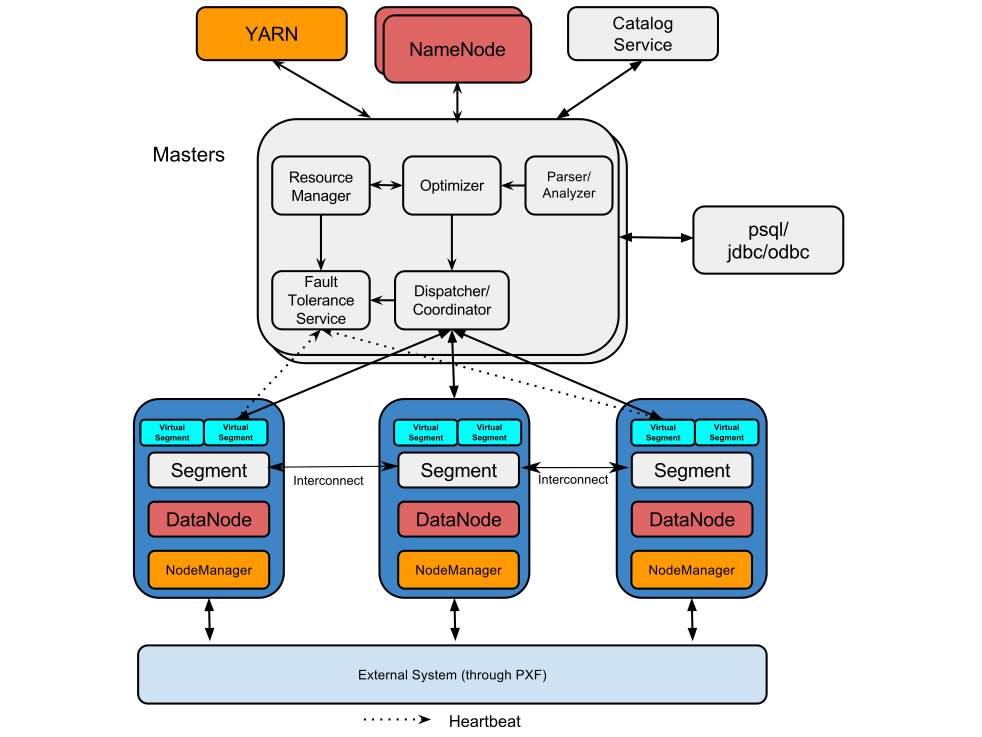
HAWQ Master
HAWQ master是系统的入口点。数据库进程接受client连接和处理发出的SQL命令。
HAWQ master解析查询、优化查询、将查询分派到segments并协调查询执行。
最终用户通过master与HAWQ交互,并可以使用诸如psql之类的客户端程序或
诸如JDBC或ODBC之类的应用程序编程接口(api)连接到数据库。
Master是全局系统目录(global system catalog)所在的位置。global system catalog是一组系统表,其中包含关于HAWQ系统本身的元数据。
主机不包含任何用户数据;数据只存放在HDFS上。
主机验证客户机连接,处理传入的SQL命令,在segments之间分配工作负载,
协调每个segment返回结果,并将最终结果显示给client程序。
HAWQ Segment
在HAWQ中,segments是同时处理数据的单元。
每个主机上只有一个物理segment。
对于每个query slice,每个segment 启动多个查询执行器(qes)。
这使得单个segment的行为类似于多个virtual segments,这使得HAWQ能够更好地利用所有可用资源。
注:在本文档中,当我们单独提及segment时,我们指的是物理segment。
virtual segment的行为就像QEs的容器。
对于查询的每个slice,每个virtual segment都有一个QE。
使用的virtual segment数决定查询的并行度(DOP)。
segment与master不同,因为它:
- 是无状态的。
- 不存储每个数据库和表的元数据。
- 不在本地文件系统上存储数据。
Master将SQL请求与要处理的相关元数据信息一起发送到segment。
元数据包含所需表的HDFS url。
segment使用这个URL访问相应的数据。
HAWQ Interconnect
interconnect是HAWQ的网络层。
当用户连接到数据库并发出查询指令时,将在每个segment上创建处理查询的进程。interconnect指的是segment之间的进程间通信,以及这种通信所依赖的网络基础设施。interconnect使用标准以太网交换结构。
默认情况下,互连使用UDP(用户数据报协议)通过网络发送消息。
除了UDP所提供的功能外,HAWQ软件还可以执行其他数据包验证。
这意味着可靠性等价于传输控制协议(TCP),并且性能和可伸缩性超过了TCP。
如果互连使用TCP,则HAWQ的可伸缩性限制为1000个segment实例。
当使用UDP作为interconnect的当前默认协议时,segment实例个数没有限制。
HAWQ Resource Manager
HAWQ资源管理器从YARN获取资源并响应资源请求。
资源由HAWQ资源管理器缓存以支持低延迟查询。
HAWQ资源管理器在standalone模式下可以独立运行;在此配置下,HAWQ自行管理资源,而无需使用YARN。
有关HAWQ资源管理的更多详细信息,请参见HAWQ如何管理资源_待定?。
HAWQ Catalog Service
HAWQ catalog service 存储所有元数据,例如UDF/UDT信息、关系信息、安全信息和数据文件位置。
HAWQ Fault Tolerance Service
HAWQ容错服务(FTS)负责检测segment故障并接收来自segment的心跳信号。
有关此服务的更多信息,请参阅了解容错服务_待定?。
HAWQ Dispatcher
HAWQ调度器将查询计划分派到选定的segment子集,并协调segment执行查询。
dispatcher和HAWQ资源管理器是负责查询和执行查询所需资源的动态调度的主要组件。
表分配和存储
HAWQ将所有表数据(系统表除外)存储在HDFS中。
用户创建表时,元数据存储在master的本地文件系统中,表内容存储在HDFS中。
为了简化表数据管理,一个关系的所有数据都保存在一个HDFS文件夹下。
对于所有HAWQ表存储格式AO(Append Only)和Parquet,数据文件(一批文件)都是可拆分的,
因此HAWQ可以分配多个virtual segments来同时使用一个数据文件(其中某一个文件)。这增加了查询并行度。
/table/01_data <---- Vseg
/table/02_data <---- Vseg
/table/03_data <---- Vseg
/table/04_data <---- Vseg
/table/05_data <---- Vseg
/table/06_data <---- Vseg
Table Distribution Policy 表分布策略
HAWQ 中的默认表分配策略是随机的(random)。
随机分布(random)的表比散布分布式(distributed)表具有一些好处。
例如,群集扩展后,HAWQ 可以自动使用更多资源,而无需重新分配数据。
对于大型表,再分配非常昂贵,在基础 HDFS 在重新平衡或 DataNode 故障期间重新分配其数据后,随机分布表的数据定位(data locality)更好。当集群大时,这种情况很常见。
另一方面,对于某些查询,散列分布式(distributed)表比随机分布的(random)表更快。
例如,散列分布式(distributed)表对某些 TPC-H 查询具有一些性能优势。您应该选择最适合应用方案的分配策略。
Data Locality 数据定位
数据分布在 HDFS 数据节点中。
由于(remote read)远程读取涉及网络 I/O,(Data Locality)数据定位算法可提高本地读取比。
HAWQ 在将数据块分配给virtual segments时考虑了三个方面:
- 本地读比率
- 文件读取的连续性
- virtual segments之间的数据平衡
External Data Access 外部数据访问
HAWQ 可以使用 HAWQ 扩展框架 (PXF) 访问外部文件中的数据。
PXF 是一个可扩展的框架,允许 HAWQ 以可读或可写的外部表访问外部源中的数据。(即PXF的外部表)
PXF 内置连接器,用于访问 HDFS 文件、Hive表和 HBase 表内的数据。
PXF 还与HCatalog集成,直接hive表。
有关详细信息,请参阅使用PXF使用手册_待定?。
用户可以创建自定义的 PXF 连接器来访问其他并行数据存储或处理引擎。
连接器是使用 PXF API 的插件。有关更多信息,请参阅 PXF 外部表和 API_待定?。
弹性查询执行运行时间
HAWQ 使用动态分配的virtual segments来提供用于查询执行的资源。
在 HAWQ 1.x 中,用于运行查询的segment的数量(计算资源载体)是固定的,
无论基础查询是需要大量资源的大查询还是需要少量资源的小查询。
此架构很简单,但它使用资源效率低下。
为了解决此问题,HAWQ 现在使用基于virtual segments的弹性查询执行运行时间功能。
HAWQ 根据查询成本按需分配virtual segments。
换句话说,对于大查询,HAWQ 启动大量virtual segments,而对于小查询,HAWQ 启动的virtual segments更少。
存储
在 HAWQ 中,调用的segment的数量因查询成本而异。
为了简化表数据管理,一个关系的所有数据都保存在一个 HDFS 文件夹下。
对于所有 HAWQ 表存储格式、AO (Append-Only)和 Parquet,它们的数据文件都是可拆分的,所以HAWQ 可以分配多个virtual segments同时消耗一个数据文件(**个人理解是不同的Vseg访问TABLE对应HDFS文件下的不同数据<这里数据是可拆分的>**,这里对应的HDFS文件就是文章中的一个数据文件的意思),以增加查询的平行性。
Physical Segments 和 Virtual Segments
在 HAWQ 中,只需要在一个主机上安装一个Physical Segments,即可在主机上启动多个Virtual Segments可以开始运行查询。
HAWQ 按需分配分布于不同主机的多个Virtual Segments,以运行一个查询。
Virtual segments 是内存和 CPU 等资源的载体(容器)。
查询由Virtual Segments中的 query executors ( QE )执行。
注意:在此文档中,当我们通常所说的segment ,默认指的是Physical Segments。
Virtual Segment 分配策略
根据Virtual Segment分配策略分配不同数量的Virtual Segments。以下因素决定用于查询的Virtual Segments的数量:
- 查询运行时间可用的资源
- 查询成本(SQL的cost)
- 表的分布:换句话说,randomly表和distributed表
- 查询是否涉及 UDF 和外部表
- 特定的服务器配置参数,例如
hawq_rm_nvseg_perquery_limit和hash表查询的default_hash_table_bucket_number
资源管理
HAWQ 提供了多种资源管理方法,包括多个用户可配置的选项,包括与 YARN 资源管理的集成。
HAWQ 能够使用以下机制管理资源:
全局资源管理。您可以将 HAWQ 与 YARN 资源管理器集成,根据需要请求或返回资源。如果您不将 HAWQ 与 YARN 集成,HAWQ 将专门消耗集群资源并管理自己的资源。如果您将 HAWQ 与 YARN 集成,则 HAWQ 会自动从 YARN 获取资源,并通过其内部定义的资源队列管理获得的资源。当不再使用资源时,资源会自动返回到 YARN。
- 用户定义了不同级别的资源队列。HAWQ 管理员或超级使用者设计并定义资源队列,以便资源队列可以组织资源分配用于查询。
- 查询运行时的动态资源配置。HAWQ 根据资源队列定义动态分配资源。HAWQ 会根据运行(或排队)查询和资源队列容量自动分配资源。
- virtual segments和query的资源限制。您可以配置 HAWQ 来强制限制virtual segments和使用的资源队列的 CPU 和内存的query使用。
有关 HAWQ 资源管理及其工作原理的更多详细信息,请参阅管理资源_待定?。
HDFS Catalog 缓存
HDFS Catalog 缓存是 HAWQ master用来确定 HDFS 表数据分布信息的缓存服务。
HDFS 在 RPC 处理方面进展缓慢,尤其是在并发请求数量较高时。
为了决定哪个HAWQ segments处理数据的哪一部分,HAWQ 需要来自 HDFS NameNodes的数据位置信息。
HDFS Catalog 缓存用于缓存数据位置信息并加速 HDFS RPC。
HAWQ管理工具
HAWQ 管理工具合并为一个 hawq 命令。
hawq 命令可以单独启动、启动和停止每个segment,并支持集群的动态扩展。
有关 HAWQ 中可用的所有工具列表,请参阅 HAWQ 管理工具参考_待定?。
高可用性、冗余性和故障容错
in this topic:
i.高可用
ii.Segment故障容错
iii.内部连接冗余性
HAWQ 通过系统冗余确保集群的高可用性。
HAWQ 部署利用平台硬件冗余,例如HAWQ master catalog的 RAID、segment的 JBOD 和互连层的网络冗余。
在软件级别上,HAWQ 通过master镜像和双集群维护提供冗余。
此外,HAWQ 支持高可用的HDFS NameNode配置。
为了保持集群健康,HAWQ 使用基于心跳和按需探针协议的故障耐受性服务。
它可以动态识别新添加的节点,并在节点无法使用时从群集中删除它。
高可用
HAWQ 采用多种机制来确保高可用性。最重要的机制是针对HAWQ的,包括以下内容:
- Master镜像。集群在primary master异常失败时,具有standby master主机备份可用。
- 双集群。管理员可以创建一个辅助群集,并通过双 ETL 或备份和还原机制将其数据与主集群同步。
除了在 HAWQ 级别上管理的高可用性外,您还可以通过实现 NameNodes 的高可用性功能,为 HAWQ 提供高可用性。
请参阅 HAWQ 文件空间和启用高可用的 HDFS_待定?。
Segment故障容错
在 HAWQ 中,这些segments是无状态的。这确保了更快的恢复和更好的可用性。
当segments失败时,segments被从资源池中删除。查询不再发送到该segment。
当该segment再次运行时,Fault Tolerance Service会验证其状态,并将该段重新添加到资源池中。
内部连接冗余性
互连 interconnect是指该通信所依赖的segments和网络基础设施之间的过程间通信。
您可以通过在网络上部署双千兆以太网交换机和向 HAWQ 主机(master and segment)服务器部署冗余千兆网络连接来实现高度可用的互连。
为了在 HAWQ 中使用多个 NIC,NIC做bond是必须的。
文档信息
- 本文作者:fei
- 本文链接:https://ayee1616166.github.io/2021/02/26/ApacheHAWQ_SystemOverview_02/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)