In this topic:
i.Overview
ii.Prerequisites
iii.Lessons
Overview
本教程提供了快速介绍,让您使用Hawq安装启动和运行。您将被引入基本的Hawq功能,包括群集管理,数据库创建和简单查询。您还将熟悉使用Hawq扩展框架(PXF)来访问和查询外部HDFS数据源。
Prerequisites
确保您有一个运行的hawq 2.x单或多节点群集。您可以选择使用:
- HAWQ分布式商业产品,如Pivotal HDB。
- HAWQ sandbox virtual machine或HAWQ docker environment.环境。
- Hawq的编译和安装参考source。
Lessons
本指南包括以下内容和练习:
Lesson 1: Runtime Environmen - 检查并设置Hawq运行时环境。
Lesson 2: Cluster Administration - 执行常见的Hawq群集管理活动。
Lesson 3: Database Administration - 数据库管理 - 执行常见的Hawq数据库管理活动。
Lesson 4: Sample Data Set and HAWQ Schemas - 示例数据集和Hawq模式 - 下载教程数据和工作文件,创建零售演示架构,将数据加载到HDFS。
Lesson 5: HAWQ Tables - Hawq表 - 创建和查询Hawq管理表。
Lesson 6: HAWQ Extension Framework (PXF) - HAWQ扩展框架(PXF) - 使用PXF访问外部HDFS数据。
Lesson 1 - Runtime Environment
in this topic
i.先决条件
iii.概括
本节向您介绍HAWQ运行时环境。您将检查HAWQ安装,设置HAWQ环境并执行HAWQ管理命令。如果安装在您的环境中,您还将浏览Ambari管理控制台。
先决条件
- 安装HAWQ商业产品发行版或
HAWQ sandbox virtual machine或docker环境,或从源代码构建和安装HAWQ。确保正确配置了HAWQ安装。 - 记下HAWQ master的hostname 或IP。
- HAWQ管理用户名为
gpadmin。这是用于管理HAWQ群集的用户帐户。要执行本教程中的练习,您必须:- 获取
gpadmin用户凭证。 - 确保您HAWQ运行时环境被配置为 使得HAWQ管理员用户
gpadmin可以访问HDFS Hadoop的系统帐户(命令hdfs,hadoop)经由sudo不用提供密码。 - 获取Ambari UI用户名和密码(如果在HAWQ部署中安装了Ambari,则为可选)。默认的Ambari用户名和密码均为
admin。
- 获取
练习:设置您的HAWQ运行时环境
HAWQ安装一个脚本,该脚本用来设置HAWQ集群环境。
该greenplum_path.sh脚本位于您的HAWQ根安装目录中,$PATH和其他环境变量用于查找HAWQ文件。
最重要的是,greenplum_path.sh将$GPHOME环境变量设置为指向HAWQ安装的根目录。如果从产品发行版安装了HAWQ,或者正在运行HAWQ sandbox environment,则HAWQ根目录通常为/usr/local/hawq。如果您从源代码构建HAWQ或下载了压缩包,则$GPHOME可能会有所不同。
执行以下步骤来设置您的HAWQ运行时环境:
使用
gpadmin用户凭据登录到HAWQ master;您可能不需要提供密码:$ ssh gpadmin@<master> Password: gpadmin@master$通过执行
greenplum_path.sh文件来设置您的HAWQ操作环境。如果您从源代码构建HAWQ或下载了压缩包,则将路径替换为已安装或解压缩的greenplum_path.sh文件(例如/opt/hawq-2.1.0.0/greenplum_path.sh):gpadmin@master$ source /usr/local/hawq/greenplum_path.shsource greenplum_path.sh会自动配置下来相关的环境变量:$GPHOME$PATH包括HAWQ$GPHOME/bin/目录$LD_LIBRARY_PATH包含$GPHOME/lib/(HAWQ库包)
gpadmin@master$ echo $GPHOME /usr/local/hawq/. gpadmin@master$ echo $PATH /usr/local/hawq/./bin:/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/gpadmin/bin gpadmin@master$ echo $LD_LIBRARY_PATH /usr/local/hawq/./lib注意:您必须先
source greenplum_path.sh才能调用任何HAWQ命令。编辑您的(
gpadmin).bash_profile或其他Shell初始化文件,加入source greenplum_path.sh,gpadmin用户登陆时候相关环境变量就会预先加载好。例如,添加:source /usr/local/hawq/greenplum_path.sh在shell初始化文件中设置特定的HAWQ的环境变量。包括
PGDATABASE,PGHOST,PGOPTIONS,PGPORT,和PGUSER.您可能不需要设置这些环境变量。例如,如果您使用自定义的HAWQ master端口号,则通过PGPORT在shell初始化文件中设置环境变量来将此端口号设置为默认端口号;否则,请使用默认端口号。添加:export PGPORT=5432通过提供端口选项值的默认值,设置可以
PGPORT简化psql调用。同样,通过提供数据库选项值的默认值,设置可以
PGDATABASE简化psql调用。检查您的HAWQ安装:
gpadmin@master$ ls $GPHOME bin docs etc greenplum_path.sh include lib sbin shareHAWQ命令行实用程序位于中
$GPHOME/bin。$GPHOME/lib包括HAWQ和PostgreSQL库。查看您的HAWQ群集的当前状态,如果尚未运行,请启动该群集。实际上,您将执行不同的过程,具体取决于您是通过命令行还是使用Ambari管理集群。在本教程中向您介绍了这两种方法后,课程将重点放在命令行说明上,因为并非每个HAWQ部署都将利用Ambari。
命令行:
gpadmin@master$ hawq state Failed to connect to database, this script can only be run when the database is up.如果您的集群未运行,请启动它:
gpadmin@master$ hawq start cluster 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-Prepare to do 'hawq start' 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-You can find log in: 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-/home/gpadmin/hawqAdminLogs/hawq_start_20170411.log 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-GPHOME is set to: 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-/usr/local/hawq/. 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-Start hawq with args: ['start', 'cluster'] 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-Gathering information and validating the environment... 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-No standby host configured 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-Start all the nodes in hawq cluster 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-Starting master node 'master' 20170411:15:54:47:357122 hawq_start:master:gpadmin-[INFO]:-Start master service 20170411:15:54:48:357122 hawq_start:master:gpadmin-[INFO]:-Master started successfully 20170411:15:54:48:357122 hawq_start:master:gpadmin-[INFO]:-Start all the segments in hawq cluster 20170411:15:54:48:357122 hawq_start:master:gpadmin-[INFO]:-Start segments in list: ['segment'] 20170411:15:54:48:357122 hawq_start:master:gpadmin-[INFO]:-Start segment service 20170411:15:54:48:357122 hawq_start:master:gpadmin-[INFO]:-Total segment number is: 1 ..... 20170411:15:54:53:357122 hawq_start:master:gpadmin-[INFO]:-1 of 1 segments start successfully 20170411:15:54:53:357122 hawq_start:master:gpadmin-[INFO]:-Segments started successfully 20170411:15:54:53:357122 hawq_start:master:gpadmin-[INFO]:-HAWQ cluster started successfully获取集群的状态:
gpadmin@master$ hawq state 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- HAWQ instance status summary 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------ 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Master instance = Active 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- No Standby master defined 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Total segment instance count from config file = 1 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------ 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Segment Status 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------ 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Total segments count from catalog = 1 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Total segment valid (at master) = 1 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Total segment failures (at master) = 0 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Total number of postmaster.pid files missing = 0 20170411:16:39:18:370305 hawq_state:master:gpadmin-[INFO]:-- Total number of postmaster.pid files found = 1返回的状态信息包括Master的状态,Standby master,segment实例的数量,并且对于每个segment,有效和失败的数量。
Ambari:
如果您的部署包括Ambari服务器,请执行以下步骤以启动并查看HAWQ群集的当前状态。
- 在您喜欢的(受支持的)浏览器窗口中输入以下URL,以启动Ambari管理控制台:
<ambari-server-node>:8080 登录与Ambari凭据(默认
admin:admin)和查看仪表盘Ambari: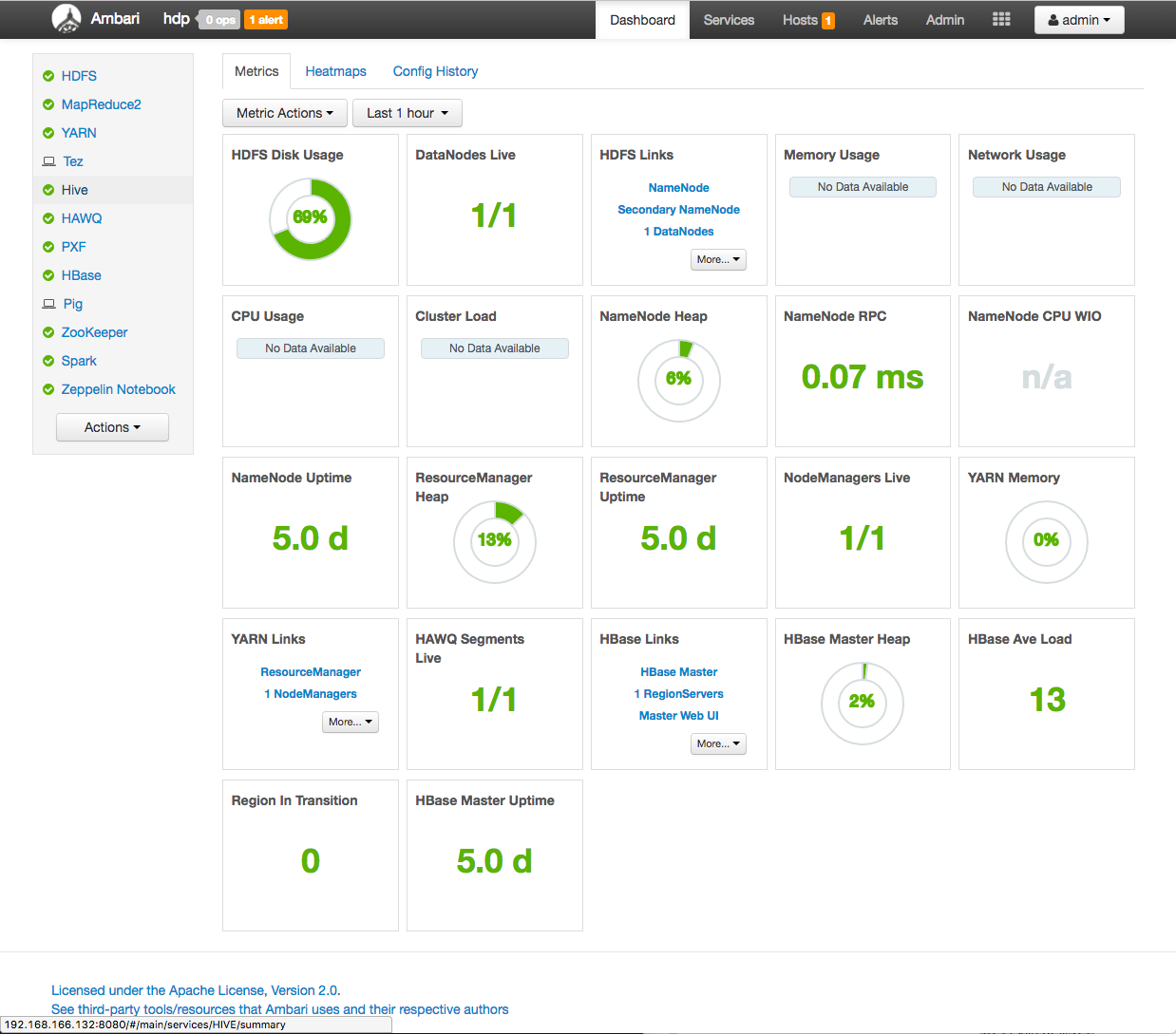
Ambari仪表板提供HAWQ集群运行状况的概览状态。左侧面板中提供了每个正在运行的服务及其状态的列表。主显示区域包括一组可配置的标题,这些标题提供了有关群集的特定信息,包括HAWQ segment状态,HDFS磁盘使用情况和资源管理指标。
导航到左窗格中列出的HAWQ服务。如果服务未运行(例如,服务名称左侧没有绿色对勾),请通过单击HAWQ服务名称,然后从“服务操作”菜单按钮中选择“启动”操作来启动HAWQ群集。
- 通过单击管理按钮并选择“退出”下拉菜单项,退出Ambari控制台。
- 在您喜欢的(受支持的)浏览器窗口中输入以下URL,以启动Ambari管理控制台:
概括
您的HAWQ集群现在正在运行。有关更多信息:
- HAWQ文件和目录标识HAWQ文件和目录及其安装位置。
- 环境变量包括HAWQ特定于部署的环境变量的完整列表。
- 运行HAWQ群集概述了组成HAWQ群集的组件,包括用户(管理和操作),部署系统(HAWQ master standby 和 segments),数据库和数据源。
第2课介绍了基本的HAWQ群集管理活动和命令。
Lesson 2 - Cluster Administration
in this topic
i.先决条件
v.概括
HAWQgpadmin管理用户对所有HAWQ数据库和HAWQ群集管理命令具有超级用户功能。
HAWQ配置参数影响HAWQ群集和单个HAWQ节点的行为。
本课介绍基本的HAWQ群集管理任务。您将查看和更新HAWQ配置参数。
注意:在安装HAWQ之前,您或管理员选择使用命令行或使用Ambari UI来配置和管理HAWQ群集。在本课程中,您将执行命令行和Ambari练习来管理HAWQ集群。尽管同时向您介绍了命令行和Ambari HAWQ群集管理模式,但不应混为一谈。
先决条件
确保已设置HAWQ运行时环境,并且HAWQ群集已启动并正在运行。
练习:从命令行查看和更新HAWQ配置
如果选择从命令行管理HAWQ群集,则将使用该hawq实用程序执行许多管理功能。该hawq命令行实用程序提供子包括start,stop,config,和state。
在本练习中,您将使用命令行查看和设置HAWQ服务器配置参数。
执行以下步骤以查看HAWQ HDFS文件空间URL并设置pljava_classpath服务器配置参数:
所述
hawq_dfs_url配置参数识别的HDFS的NameNode(或HDFS NameService如果HDFS已启用高可用)主机,端口和HAWQ文件空间位置。显示此参数的值:gpadmin@master$ hawq config -s hawq_dfs_url GUC : hawq_dfs_url Value : <hdfs-namenode>:8020/hawq_data记下 返回的主机名或IP地址,Lesson 6: HAWQ Extension Framework (PXF)
HAWQ PL / Java
pljava_classpath服务器配置参数标识HAWQ PL / Java扩展使用的classpath路径。查看当前pljava_classpath配置参数设置:gpadmin@master$ hawq config -s pljava_classpath GUC : pljava_classpath Value :当前显示表示未设置该值。
您的HAWQ安装中包含一个示例PL / Java JAR文件。设置
pljava_classpath包括examples.jar:gpadmin@master$ hawq config -c pljava_classpath -v 'examples.jar' GUC pljava_classpath does not exist in hawq-site.xml Try to add it with value: examples.jar GUC : pljava_classpath Value : examples.jar信息
GUC pljava_classpath does not exist in hawq-site.xml; Try to add it with value: examples.jar表示HAWQ找不到先前的设置,pljava_classpath并尝试将此配置参数设置为examples.jar,-v选项会将信息写入HAWQ配置文件。设置配置参数后,必须重新加载HAWQ配置:
gpadmin@master$ hawq stop cluster --reload 20170411:19:58:17:428600 hawq_stop:master:gpadmin-[INFO]:-Prepare to do 'hawq stop' 20170411:19:58:17:428600 hawq_stop:master:gpadmin-[INFO]:-You can find log in: 20170411:19:58:17:428600 hawq_stop:master:gpadmin-[INFO]:-/home/gpadmin/hawqAdminLogs/hawq_stop_20170411.log 20170411:19:58:17:428600 hawq_stop:master:gpadmin-[INFO]:-GPHOME is set to: 20170411:19:58:17:428600 hawq_stop:master:gpadmin-[INFO]:-/usr/local/hawq/. 20170411:19:58:17:428600 hawq_stop:master:gpadmin-[INFO]:-Reloading configuration without restarting hawq cluster Continue with HAWQ service stop Yy|Nn (default=N): >如上面的INFO消息中所述,重新加载配置实际上并没有停止集群。
HAWQ提示您确认操作。输入
y以确认:> y 20170411:19:58:22:428600 hawq_stop:master:gpadmin-[INFO]:-No standby host configured 20170411:19:58:23:428600 hawq_stop:master:gpadmin-[INFO]:-Reload hawq cluster 20170411:19:58:23:428600 hawq_stop:master:gpadmin-[INFO]:-Reload hawq master 20170411:19:58:23:428600 hawq_stop:master:gpadmin-[INFO]:-Master reloaded successfully 20170411:19:58:23:428600 hawq_stop:master:gpadmin-[INFO]:-Reload hawq segment 20170411:19:58:23:428600 hawq_stop:master:gpadmin-[INFO]:-Reload segments in list: ['segment'] 20170411:19:58:23:428600 hawq_stop:master:gpadmin-[INFO]:-Total segment number is: 1 .. 20170411:19:58:25:428600 hawq_stop:master:gpadmin-[INFO]:-1 of 1 segments reload successfully 20170411:19:58:25:428600 hawq_stop:master:gpadmin-[INFO]:-Segments reloaded successfully 20170411:19:58:25:428600 hawq_stop:master:gpadmin-[INFO]:-Cluster reloaded successfully进行的配置参数值更改
hawq config是在整个系统范围内进行的;它们会传播到整个集群的所有段。
练习:通过Ambari查看HAWQ群集的状态
您可以选择使用Ambari来管理HAWQ部署。Ambari Web UI为HAWQ群集管理活动提供了图形化的前端。
执行以下步骤,通过Ambari Web控制台查看HAWQ群集的状态:
启动Ambari Web UI:
<ambari-server-node>:8080Ambari在端口8080上运行。
使用Ambari用户凭据登录到Ambari UI。
显示Ambari UI仪表板窗口。
从左窗格的服务列表中选择HAWQ服务。
将显示“ HAWQ服务”页面的“摘要”选项卡。该页面包括一个“摘要”窗格,用于标识群集中的HAWQ主节点和所有HAWQ段节点。“指标”窗格包括一组特定于HAWQ的指标图块。
通过从“服务操作”按钮下拉菜单中选择“运行服务检查”项并执行确认操作,来执行HAWQ服务检查操作。
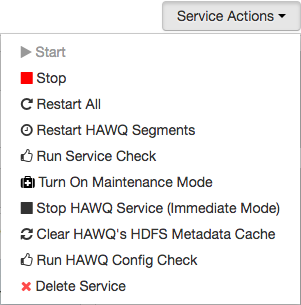
显示“后台操作正在运行”对话框。此对话框标识在HAWQ群集上执行的所有与服务相关的操作。
从“操作”列顶部选择最新的HAWQ服务检查操作。从“ HAWQ服务检查”对话框中选择HAWQ主主机名,然后选择“检查HAWQ”任务。
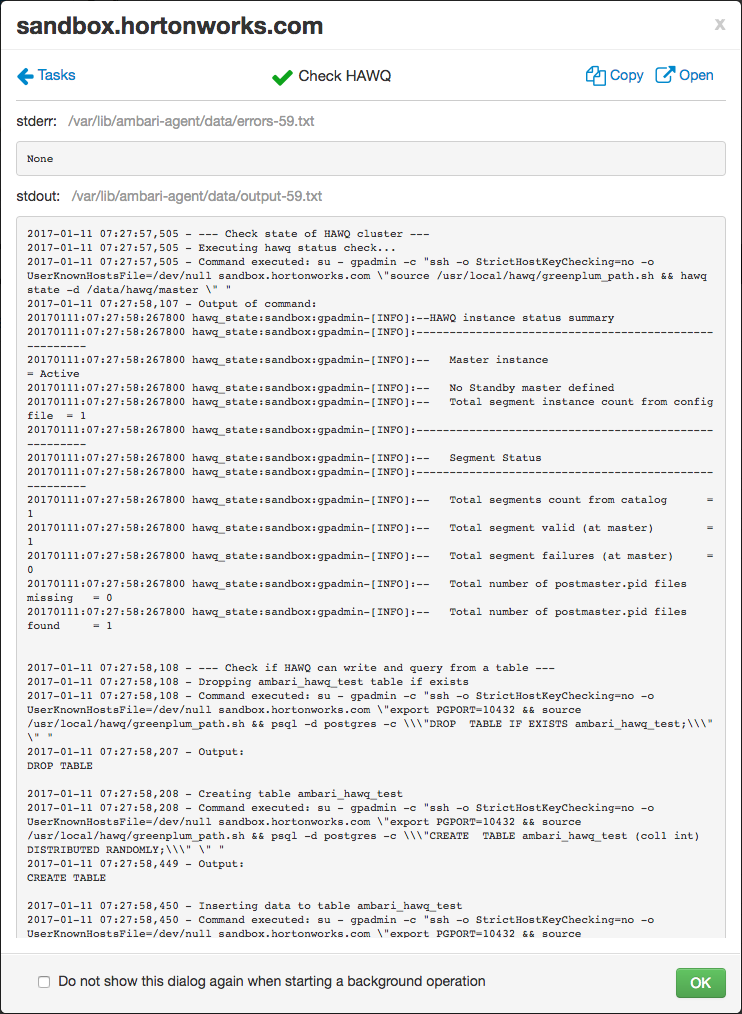
“检查HAWQ”任务对话框显示服务检查操作的输出。此操作将返回您的HAWQ群集的状态,以及Ambari执行的HAWQ数据库操作测试的结果。
练习:通过Ambari查看和更新HAWQ配置
执行以下步骤以查看HDFS节点名称,并通过Ambari设置HAWQ PL / Java pljava_classpath配置参数和值:
导航到HAWQ服务页面。
选择配置选项卡以查看当前特定于HAWQ的配置设置。
显示的HAWQ常规设置包括master数据和segment数据以及临时目录位置,以及特定的资源管理参数。
选择“高级”选项卡以查看其他HAWQ参数设置。
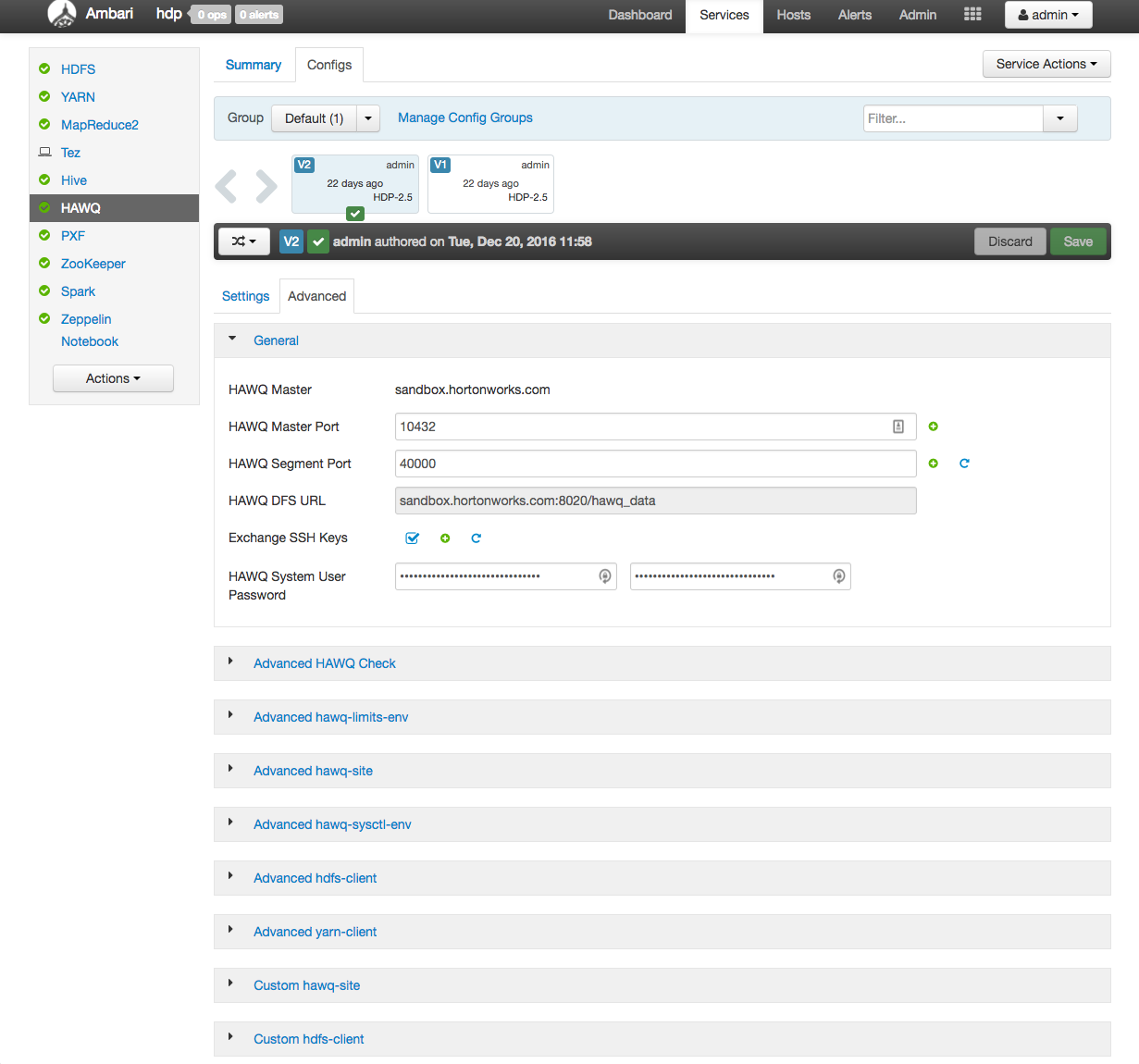
将打开“常规”下拉窗格。此选项卡显示包括HAWQ主服务器主机名以及主端口和段端口号的信息。
在“常规”窗格中找到HAWQ DFS URL配置参数设置。该值应与上一练习中返回的值匹配。记下HDFS NameNode主机名或IP地址(如果以前没有这样做的话)。
hawq config -s hawq_dfs_url注意:HDFS服务的“配置”>“高级配置”选项卡还标识HDFS NameNode主机名。
**“高级
”**和“**自定义 ”**下拉窗格提供对HAWQ和其他群集组件的高级配置设置的访问。选择**高级hawq站点**下拉菜单。 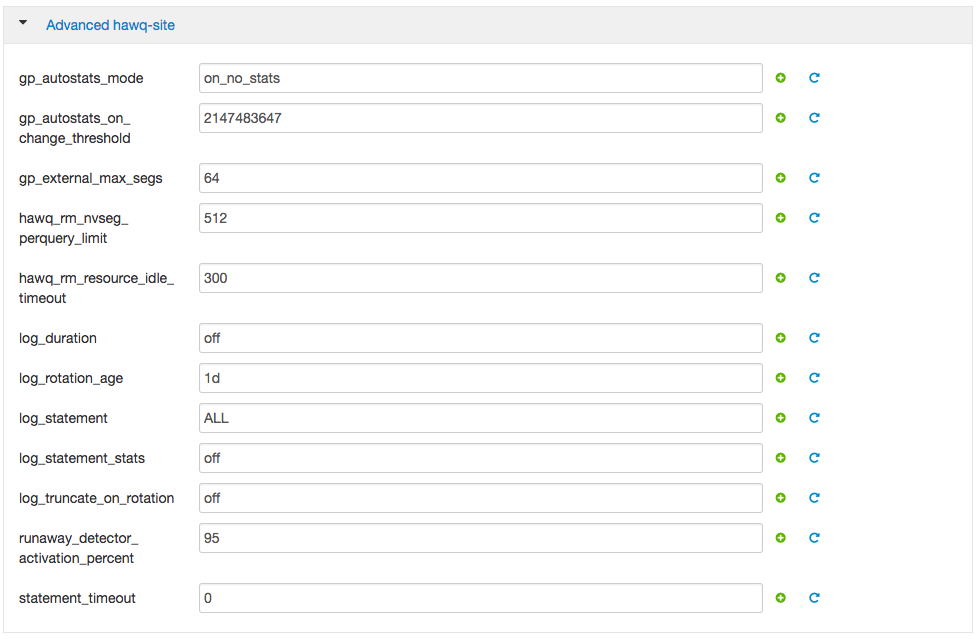
特定的HAWQ配置参数和值显示在窗格中。将鼠标指针悬停在值字段上,以显示特定配置参数的工具提示描述。
选择“自定义hawq网站”下拉菜单。
当前配置的自定义参数和值显示在窗格中。如果未设置任何配置参数,则该窗格将为空。
选择添加属性…。
显示“添加属性”对话框。该对话框包括Type,Key和Value输入字段。
在“添加属性”对话框中选择单一属性添加模式(单个标签图标),然后填写以下字段:
Key:pljava_classpath Value:examples.jar
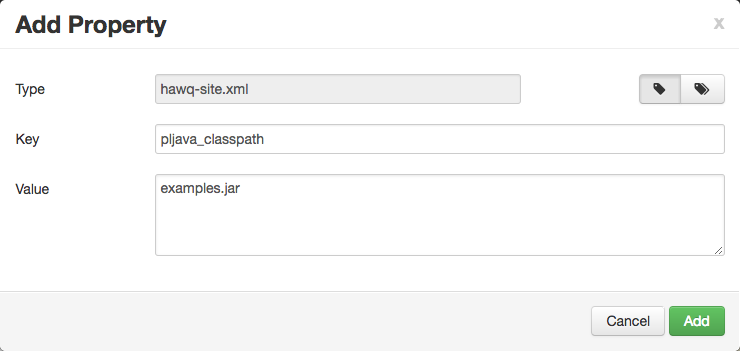
添加自定义属性,然后保存更新的配置,可以选择在“保存配置”对话框中提供一个注释。

注意窗口右上角现在的橙色“重新启动”按钮。通过Ambari添加或更新配置参数值后,必须重新启动HAWQ服务。
选择橙色的“重新启动”按钮以重新启动所有受影响的HAWQ节点。
您可以从“后台操作正在运行”对话框中监视重新启动操作。
重新启动操作完成后,通过单击管理按钮并选择“退出”下拉菜单项,退出Ambari控制台。
概括
在本课程中,您查看了HAWQ集群的状态,并学习了如何更改集群配置参数。
有关HAWQ服务器配置参数的其他信息,请参阅《服务器配置参数参考_待定??》。
下表列出了本教程练习中使用的HAWQ管理命令。有关特定HAWQ管理命令的详细信息,请参阅《HAWQ管理工具参考_待定??》。
| Action | Command |
|---|---|
| 获取HAWQ集群状态 | $ hawq state |
| 启动/停止/重新启动HAWQ <object>(cluster, master, segment, standby, allsegments) | $ hawq start <object>$ hawq stop <object> $ hawq restart <object> |
| 列出所有HAWQ配置参数及其当前设置 | $ hawq config -l |
| 显示指定HAWQ配置参数的当前设置 | $ hawq config -s <param-name> |
| 添加/更改HAWQ配置参数的值(仅命令行管理的HAWQ群集) | $ hawq config -c <param-name> -v <value> |
| 重新加载HAWQ配置 | $ hawq stop cluster --reload |
Lesson 3: Database Administration
in this topic:
i.先决条件
iii.练习:使用psql进行表操作
iv.概括
HAWQ gpadmin用户和被授予必要特权的其他用户可以执行SQL命令来创建HAWQ数据库和表。
这些命令可以通过脚本,程序或从psql客户端实用程序中调用。
本课介绍了使用psql的基本HAWQ数据库管理命令和任务。
您将创建一个数据库和一个简单的表,并向该表中添加数据并对其进行查询。
先决条件
确保已设置HAWQ运行时环境_待定?,并且HAWQ群集已启动并正在运行。
练习: 创建HAWQ教程数据库
在本练习中,您将使用psql命令行实用程序来创建HAWQ数据库。
启动psql子系统:
gpadmin@master$ psql -d postgres输入psql解释器,连接到postgres数据库。 postgres是在HAWQ安装期间创建的默认模板数据库。
psql (8.2.15) Type "help" for help. postgres=#psql提示符是数据库名称,后跟
=#或=>。=#将会话标识为数据库超级用户的会话。非超级用户的默认psql提示是=>。创建一个名为
hawqgsdb的数据库:postgres=# CREATE DATABASE hawqgsdb; CREATE DATABASE这
;在CREATE DATABASE语句的末尾指示psql解释该命令。就是说分号作为一条完整指令的结束。连接到您刚刚创建的
hawqgsdb数据库:postgres=# \c hawqgsdb You are now connected to database "hawqgsdb" as user "gpadmin". hawqgsdb=#使用
psql \l命令列出所有HAWQ数据库:hawqgsdb=# \l List of databases Name | Owner | Encoding | Access privileges -----------------+---------+----------+------------------- hawqgsdb | gpadmin | UTF8 | postgres | gpadmin | UTF8 | template0 | gpadmin | UTF8 | template1 | gpadmin | UTF8 | (4 rows)如上所示,HAWQ在安装期间创建了两个附加的模板数据库,即template0和template1。您的HAWQ群集可能会列出其他数据库。
退出
sql:hawqgsdb=# \q
练习: 使用psql进行表操作
您可以通过psql实用程序(HAWQ数据库的交互式前端)来管理和访问HAWQ数据库和表。
在本练习中,您将使用psql创建简单的HAWQ表,向其中添加数据以及查询简单的HAWQ表。
启动psql子系统:
gpadmin@master$ psql -d hawqgsdb-d hawqgsdb选项指示psql直接连接到hawqgsdb数据库。创建一个名为first_tbl的表,该表具有一个名为i的整数列:
hawqgsdb=# CREATE TABLE first_tbl( i int ); CREATE TABLE显示有关表first_tbl的描述性信息:
hawqgsdb=# \d first_tbl Append-Only Table "public.first_tbl" Column | Type | Modifiers --------+---------+----------- i | integer | Compression Type: None Compression Level: 0 Block Size: 32768 Checksum: f Distributed randomlyfirst_tbl是HAWQpublicSCHEMA中的表。first_tbl具有单个整数列,是在不压缩的情况下创建的,并且是随机分布的。向first_tbl添加一些数据:
hawqgsdb=# INSERT INTO first_tbl VALUES(1); INSERT 0 1 hawqgsdb=# INSERT INTO first_tbl VALUES(2); INSERT 0 1每个
INSERT命令都将一行添加到first_tbl,第一个命令添加一个值i = 1的行,第二个命令添加一个值i = 2的行。每个INSERT还显示添加的行数(INSERT 0 1)。HAWQ提供了一些内置的数据处理功能。
generate_series(<start>,<end>)函数生成一系列以<start>开头并以<end>结尾的数字。使用generate_series()HAWQ内置函数将i = 3,i = 4和i = 5的行添加到first_tbl:hawqgsdb=# INSERT INTO first_tbl SELECT generate_series(3, 5); INSERT 0 3此INSERT命令使用内建的
generate_series()函数向first_tbl添加3行,从i = 3开始,然后为每个新行写入和递增i。执行查询以返回first_tbl表中的所有行:
hawqgsdb=# SELECT * FROM first_tbl; i ---- 1 2 3 4 5 (5 rows)SELECT *命令查询first_tbl,返回所有列和所有行。SELECT还显示查询中返回的总行数。执行查询以返回i大于3的first_tbl中所有行的第i列:
hawqgsdb=# SELECT i FROM first_tbl WHERE i>3; i ---- 4 5 (2 rows)SELECT命令返回表中i大于3的2行(i = 4和i = 5)并显示i的值。退出psql子系统:
hawqgsdb=# \qpsql包含选项-c,可从shell命令行运行单个SQL命令。使用-c <sql-command>选项执行与在步骤7中运行的查询相同的查询:gpadmin@master$ psql -d hawqgsdb -c 'SELECT i FROM first_tbl WHERE i>3'设置HAWQ
PGDATABASE环境变量以标识hawqsgdb:gpadmin@master$ export PGDATABASE=hawqgsdb$PGDATABASE标识调用HAWQpsql命令时要连接的默认数据库。再次从命令行重新运行查询,这次省略了
-d选项:gpadmin@master$ psql -c 'SELECT i FROM first_tbl WHERE i>3'如果在命令行上未指定数据库,则psql尝试连接到
$PGDATABASE标识的数据库。将PGDATABASE设置添加到您的
.bash_profile中:export PGDATABASE=hawqgsdb
概括
您创建了将在以后的课程中使用的数据库。您还使用psql创建了简单的HAWQ表,将数据插入其中,并查询了该表。
有关HAWQ中SQL命令支持的信息,请参考SQL命令_待定?参考。
有关psql子系统的详细信息,请参考psql_待定?参考页。下表列出了常用的psql元命令。
| Action | Command |
|---|---|
| List databases | \l |
| List tables in current database | \dt |
| Describe a specific table | \d <table-name> |
| Execute an SQL script | \i <script-name> |
| Quit/Exit | \q |
第4课介绍了零售演示,这是在以后的课程中使用的更复杂的数据集。您将下载并检查数据集和工作文件。您还将把某些数据集加载到HDFS中。
Lesson 4 - Sample Data Set and HAWQ Schemas
in this topic:
i.先决条件
iii.练习:创建零售演示HAWQ模式
v.概括
本教程中使用的样本零售演示数据集对在线零售商店操作进行了建模。
该商店提供不同类别的产品。客户订购产品。公司将产品交付给客户。
此练习和以后的练习都在此示例数据集上运行。
数据集在一组gzip格式的.tsv(制表符分隔的值)文本文件中提供。
这些练习还引用了对数据集进行操作的脚本和其他支持文件。
在本节中,向您介绍了零售演示数据模式。
您将下载并检查数据集和工作文件。您还将把一些数据加载到HDFS中。
先决条件
确保已创建HAWQ数据库教程_待定?,并且HAWQ群集已启动并正在运行。
练习:下载零售演示数据和脚本文件
执行以下步骤以下载样本数据集和脚本:
打开一个终端窗口,并以
gpadmin用户身份登录到HAWQ主节点:$ ssh gpadmin@<master>为数据文件和脚本创建一个工作目录:
gpadmin@master$ mkdir /tmp/hawq_getstart gpadmin@master$ cd /tmp/hawq_getstart您可以选择其他基础工作目录。如果这样做,请确保拥有
hawq_getstart目录的所有路径组件都具有全部的读取和执行权限。从github下载教程工作和数据文件,并检查适当的标记/分支:
gpadmin@master$ git clone https://github.com/pivotalsoftware/hawq-samples.git Cloning into 'hawq-samples'... remote: Counting objects: 42, done. remote: Total 42 (delta 0), reused 0 (delta 0), pack-reused 42 Unpacking objects: 100% (42/42), done. Checking out files: 100% (18/18), done. gpadmin@master$ cd hawq-samples gpadmin@master$ git checkout hawq2x_tutorial将路径保存到工作文件基本目录:
gpadmin@master$ export HAWQGSBASE=/tmp/hawq_getstart/hawq-samples(如果选择了其他基础工作目录,请相应地修改命令。)
将
$HAWQGSBASE环境变量设置添加到您的.bash_profile。检查教程文件。本指南中的练习参考了hawq-samples存储库中的数据文件以及SQL和Shell脚本。具体来说:
Directory Content datasets/retail/ Retail demo data set data files ( .tsv.gzformat)tutorials/getstart/ Getting Started with HAWQ guide work files tutorials/getstart/hawq/ SQL and shell scripts used by the HAWQ tables exercises tutorials/getstart/pxf/ SQL and shell scripts used by the PXF exercises (HAWQ入门练习不使用上表中未提及的
hawq-samples存储库目录。)
练习:创建零售演示HAWQ模式
HAWQ schema是数据库的namespace。它包含诸如表,数据类型,函数和运算符之类的命名对象。通过使用前缀<schema-name>限定其名称来访问这些对象。
执行以下步骤来创建Retail演示数据模式:
启动
psql子系统:gpadmin@master$ psql hawqgsdb=#您已连接到
hawqgsdb数据库。列出HAWQ模式:
hawqgsdb=# \dn List of schemas Name | Owner --------------------+--------- hawq_toolkit | gpadmin information_schema | gpadmin pg_aoseg | gpadmin pg_bitmapindex | gpadmin pg_catalog | gpadmin pg_toast | gpadmin public | gpadmin (7 rows)每个数据库都包含一个名为
public的SCHEMA。在不指定架构的情况下创建的数据库对象将在默认SCHEMA中创建。默认的HAWQSCHEMA是public,除非您将其显式设置为另一个SCHEMA。 (稍后对此有更多介绍。)在
publicSCHEMA中显示表:hawqgsdb=#\dt public.* List of relations Schema | Name | Type | Owner | Storage --------+-----------+-------+---------+------------- public | first_tbl | table | gpadmin | append only (1 row)在第3课中,您在
publicSCHEMA中创建了first_tbl表。创建一个名为retail_demo的SCHEMA来表示Retail演示namespace:
hawqgsdb=# CREATE SCHEMA retail_demo; CREATE SCHEMAsearch_path服务器配置参数标识HAWQ应该搜索或应用对象的SCHEMA的顺序。设置SCHEMA搜索路径,使其首先包含新的retail_demoSCHEMA:hawqgsdb=# SET search_path TO retail_demo, public; SETretail_demo,即search_path中的第一个架构,将成为您的默认SCHEMA。 注意:以这种方式设置search_path只会为当前psql会话设置参数。您必须在随后的psql会话中重新设置search_path。创建另一个名为
first_tbl的表:hawqgsdb=# CREATE TABLE first_tbl( i int ); CREATE TABLE hawqgsdb=# INSERT INTO first_tbl SELECT generate_series(100,103); INSERT 0 4 hawqgsdb=# SELECT * FROM first_tbl; i ----- 100 101 102 103 (4 rows)由于未为该表显式标识任何SCHEMA,因此HAWQ在默认SCHEMA中创建了名为
first_tbl的表。由于您当前的search_pathSCHEMA排序,您的默认SCHEMA为retail_demo。通过在以下模式中显示表来验证在
first_tbl模式中是否创建了first_tbl:hawqgsdb=#\dt retail_demo.* List of relations Schema | Name | Type | Owner | Storage -------------+----------------------+-------+---------+------------- retail_demo | first_tbl | table | gpadmin | append only (1 row)查询您在第3课中创建的
first_tbl表:hawqgsdb=# SELECT * from public.first_tbl; i --- 1 2 3 4 5 (5 rows)您必须在表名前面加上public。明确标识您感兴趣的first_tbl表。
退出psql:
hawqgsdb=# \q
练习:将维度数据加载到HDFS
零售演示数据集包括下表中描述的实体。事实表由业务事实组成。
订单和订单行项目是事实表。维度表为事实表中的度量提供描述性信息。
其他实体在维度表中表示。
| Entity | Description |
|---|---|
| customers_dim | Customer data: first/last name, id, gender |
| customer_addresses_dim | Address and phone number of each customer |
| email_addresses_dim | Customer e-mail addresses |
| categories_dim | Product category name, id |
| products_dim | Product details including name, id, category, and price |
| date_dim | Date information including year, quarter, month, week, day of week |
| payment_methods | Payment method code, id |
| orders | Details of an order such as the id, payment method, billing address, day/time, and other fields. Each order is associated with a specific customer. |
| order_lineitems | Details of an order line item such as the id, item id, category, store, shipping address, and other fields. Each line item references a specific product from a specific order from a specific customer. |
执行以下步骤,将零售演示维度数据加载到HDFS中以供以后使用:
导航到
PXF脚本目录:gpadmin@master$ cd $HAWQGSBASE/tutorials/getstart/pxf使用提供的脚本,将代表维度数据的样本数据文件加载到名为
/retail_demo的HDFS目录中。该脚本在加载数据之前删除所有现有的/retail_demo目录和内容:gpadmin@master$ ./load_data_to_HDFS.sh running: sudo -u hdfs hdfs -rm -r -f -skipTrash /retail_demo sudo -u hdfs hdfs dfs -mkdir /retail_demo/categories_dim sudo -u hdfs hdfs dfs -put /tmp/hawq_getstart/hawq-samples/datasets/retail/categories_dim.tsv.gz /retail_demo/categories_dim/ sudo -u hdfs hdfs dfs -mkdir /retail_demo/customer_addresses_dim sudo -u hdfs hdfs dfs -put /tmp/hawq_getstart/hawq-samples/datasets/retail/customer_addresses_dim.tsv.gz /retail_demo/customer_addresses_dim/ ...load_to_HDFS.sh将纬度数据.tsv.gz文件直接加载到HDFS中。每个文件都加载到其各自的/retail_demo/<basename>/<basename>.tsv.gz文件路径中。查看HDFS
/retail_demo目录层次结构的内容:gpadmin@master$ sudo -u hdfs hdfs dfs -ls /retail_demo/* -rw-r--r-- 3 hdfs hdfs 590 2017-04-10 19:59 /retail_demo/categories_dim/categories_dim.tsv.gz Found 1 items -rw-r--r-- 3 hdfs hdfs 53995977 2017-04-10 19:59 /retail_demo/customer_addresses_dim/customer_addresses_dim.tsv.gz Found 1 items -rw-r--r-- 3 hdfs hdfs 4646775 2017-04-10 19:59 /retail_demo/customers_dim/customers_dim.tsv.gz Found 1 items ... Because the retail demo data exists only as `.tsv.gz` files in HDFS, you cannot immediately query the data using HAWQ. In the next lesson, you create HAWQ external tables that reference these data files, after which you can query them via PXF.
概括
在本课程中,您下载了教程数据集和工作文件,创建了retail_demo HAWQ SCHEMA,并将Retail demo维度数据加载到HDFS中。
在第5和第6课中,您将在retail_demo SCHEMA中创建和查询HAWQ内部和外部表。
Lesson 5 - HAWQ Tables
In this topic:
i.先决条件
ii.练习:创建,向HAWQ Retail演示表添加数据以及查询HAWQ Retail演示表
iii.概括
HAWQ将数据本地写入HDFS或从HDFS读取数据。
HAWQ表类似于任何关系数据库中的表,除了表行(数据)分布在集群中的不同segment上。
在本练习中,您将运行使用SQL CREATE TABLE命令创建HAWQ表的脚本。
您将使用SQL COPY命令将Retail演示事实数据加载到HAWQ表中。
然后,您将对数据执行简单和复杂的查询。
先决条件
确保您具有:
设置您的HAWQ运行时环境
创建了HAWQ数据库教程
下载了零售数据和脚本文件
创建了零售演示HAWQ模式
启动您的HAWQ集群。
练习:创建,向HAWQ Retail演示表添加数据以及查询HAWQ Retail演示表
执行以下步骤,从示例零售演示数据集中创建和加载HAWQ表。
导航到HAWQ脚本目录:
gpadmin@master$ cd $HAWQGSBASE/tutorials/getstart/hawq使用提供的脚本为Retail演示事实数据创建表:
gpadmin@master$ psql -f ./create_hawq_tables.sql psql:./create_hawq_tables.sql:2: NOTICE: table "order_lineitems_hawq" does not exist, skipping DROP TABLE CREATE TABLE psql:./create_hawq_tables.sql:41: NOTICE: table "orders_hawq" does not exist, skipping DROP TABLE CREATE TABLE注意:
create_hawq_tables.sql脚本会在尝试创建每个表之前将其删除。如果这是您第一次执行此练习,则可以放心地忽略psql“表不存在,正在跳过”消息。)让我们看一下
create_hawq_tables.sql脚本;例如:gpadmin@master$ vi create_hawq_tables.sql请注意的使用
retail_demo.SCHEMA的前缀为order_lineitems_hawq表名称:DROP TABLE IF EXISTS retail_demo.order_lineitems_hawq; CREATE TABLE retail_demo.order_lineitems_hawq ( order_id TEXT, order_item_id TEXT, product_id TEXT, product_name TEXT, customer_id TEXT, store_id TEXT, item_shipment_status_code TEXT, order_datetime TEXT, ship_datetime TEXT, item_return_datetime TEXT, item_refund_datetime TEXT, product_category_id TEXT, product_category_name TEXT, payment_method_code TEXT, tax_amount TEXT, item_quantity TEXT, item_price TEXT, discount_amount TEXT, coupon_code TEXT, coupon_amount TEXT, ship_address_line1 TEXT, ship_address_line2 TEXT, ship_address_line3 TEXT, ship_address_city TEXT, ship_address_state TEXT, ship_address_postal_code TEXT, ship_address_country TEXT, ship_phone_number TEXT, ship_customer_name TEXT, ship_customer_email_address TEXT, ordering_session_id TEXT, website_url TEXT ) WITH (appendonly=true, compresstype=zlib) DISTRIBUTED RANDOMLY;上面的
CREATE TABLE语句在retail_demoSCHEMA中创建一个名为order_lineitems_hawq的表。order_lineitems_hawq有几列。order_id和customer_id提供了进入订单事实和客户维度表的键。order_lineitems_hawq中的数据是随机分布的,并使用zlib压缩算法进行压缩。create_hawq_tables.sql脚本还会创建orders_hawq事实表。看一下
load_hawq_tables.sh脚本:gpadmin@master$ vi load_hawq_tables.sh同样,请注意表名称的前缀
retail_demo.是SCHEMA名称。 检查psql -c COPY命令:zcat $DATADIR/order_lineitems.tsv.gz | psql -d hawqgsdb -c "COPY retail_demo.order_lineitems_hawq FROM STDIN DELIMITER E'\t' NULL E'';" zcat $DATADIR/orders.tsv.gz | psql -d hawqgsdb -c "COPY retail_demo.orders_hawq FROM STDIN DELIMITER E'\t' NULL E'';"load_hawq_tables.shShell脚本使用zcat命令解压缩.tsv.gz数据文件。 SQLCOPY命令将STDIN(即zcat命令的输出)复制到HAWQ表。 COPY命令还标识文件(选项)中使用的DELIMITER和NULL字符串(’‘)。使用
load_hawq_tables.sh脚本将Retail演示事实数据加载到新创建的表中。此过程可能需要一些时间才能完成。gpadmin@master$ ./load_hawq_tables.sh使用提供的脚本来验证是否成功加载了零售演示事实表:
gpadmin@master$ ./verify_load_hawq_tables.shverify_load_hawq_tables.sh脚本的输出应与以下内容匹配:Table Name | Count ------------------------------+------------------------ order_lineitems_hawq | 744196 orders_hawq | 512071 ------------------------------+------------------------在
order_lineitems_hawq表上运行查询:gpadmin@master$ psql hawqgsdb=# SELECT product_id, item_quantity, item_price, coupon_amount FROM retail_demo.order_lineitems_hawq WHERE order_id='8467975147' ORDER BY item_price; product_id | item_quantity | item_price | coupon_amount ------------+---------------+------------+--------------- 1611429 | 1 | 11.38 | 0.00000 1035114 | 1 | 12.95 | 0.15000 1382850 | 1 | 17.56 | 0.50000 1562908 | 1 | 18.50 | 0.00000 1248913 | 1 | 34.99 | 0.50000 741706 | 1 | 45.99 | 0.00000 (6 rows)ORDER BY子句根据item_price排序。如果未指定ORDER BY列,则按将行添加到表中的顺序返回行。通过在
orders_hawq表上运行以下查询,按订单收入确定前三个邮政编码:hawqgsdb=# SELECT billing_address_postal_code, sum(total_paid_amount::float8) AS total, sum(total_tax_amount::float8) AS tax FROM retail_demo.orders_hawq GROUP BY billing_address_postal_code ORDER BY total DESC LIMIT 3;请注意,使用
sum()聚合函数可将所有订单的订单总计(total_amount_paid)和税额总计(total_tax_paid)相加。这些总计将针对每个billing_address_postal_code进行分组/汇总。 将您的输出与以下内容进行比较:billing_address_postal_code | total | tax ----------------------------+-----------+----------- 48001 | 111868.32 | 6712.0992 15329 | 107958.24 | 6477.4944 42714 | 103244.58 | 6194.6748 (3 rows)在
orders_hawq和order_lineitems_hawq表上运行以下查询,以显示所有标识product_id为1869831的订单项的product_id,item_quantity和item_price:hawqgsdb=# SELECT retail_demo.order_lineitems_hawq.order_id, product_id, item_quantity, item_price FROM retail_demo.order_lineitems_hawq, retail_demo.orders_hawq WHERE retail_demo.order_lineitems_hawq.order_id=retail_demo.orders_hawq.order_id AND retail_demo.order_lineitems_hawq.product_id=1869831 ORDER BY retail_demo.order_lineitems_hawq.order_id, product_id; order_id | product_id | item_quantity | item_price ------------+------------+---------------+------------ 4831097728 | 1869831 | 1 | 11.87 6734073469 | 1869831 | 1 | 11.87 (2 rows)退出psql子系统:
hawqgsdb=# \q
概括
在本课程中,您创建了零售订单和订单行数据并将其加载到HAWQ事实表中。您还查询了这些表,了解如何根据需要过滤数据。 在第6课中,您将使用PXF外部表来类似地访问HDFS中存储的维度数据。
Lesson 6 - HAWQ Extension Framework (PXF)
In this topic:
i.先决条件
ii.练习: 创建和查询PXF外部表
iii.练习: 查询HAWQ和PXF表
iv.概括
许多HAWQ部署中的数据可能已经驻留在外部源中。
HAWQ扩展框架(PXF)提供称为插件的内置连接器提供对此外部数据的访问。
PXF插件有助于将数据源映射到HAWQ外部表定义。
PXF与HDFS,Hive,HBase和JSON插件一起安装。
在本练习中,您将使用PXF HDFS插件执行以下操作:
- 创建PXF外部表定义
- 对您加载到HDFS中的数据执行查询
- 在HAWQ和PXF表上运行更复杂的查询
先决条件
确保您具有:
您还应该检索在查看和更新HAWQ配置中记下的HDFS NameNode的主机名或IP地址。
练习: 创建和查询PXF外部表
执行以下步骤来创建HAWQ外部表定义,以读取您先前加载到HDFS中的维度数据。
以gpadmin用户身份登录到HAWQ主节点:
$ ssh gpadmin@<master>导航到PXF脚本目录:
gpadmin@master$ cd $HAWQGSBASE/tutorials/getstart/pxf启动
psql子系统:gpadmin@master$ psql hawqgsdb=#创建一个HAWQ外部表定义,以表示您在第4课中加载到HDFS的Retail
demo customer_dim维度数据;在LOCATION子句的<namenode>字段中替换您的NameNode主机名或IP地址:hawqgsdb=# CREATE EXTERNAL TABLE retail_demo.customers_dim_pxf (customer_id TEXT, first_name TEXT, last_name TEXT, gender TEXT) LOCATION ('pxf://<namenode>:51200/retail_demo/customers_dim/customers_dim.tsv.gz?profile=HdfsTextSimple') FORMAT 'TEXT' (DELIMITER = E'\t'); CREATE EXTERNAL TABLE指定
pxf协议的CREATE EXTERNAL TABLE语句的LOCATION子句必须包括:- HAWQ群集的HDFS
<namenode>的主机名或IP地址。 - 外部数据源的位置或名称。您在上面的
customer_dim数据文件中指定了HDFS文件路径。 - 用于访问外部数据的PXF配置文件。 PXF HDFS插件支持
HdfsTextSimple配置文件,以访问分隔的文本格式数据。
指定
pxf协议和HdfsTextSimple配置文件的CREATE EXTERNAL TABLE语句的FORMAT子句必须标识TEXT格式,并包括用于访问外部数据源的DELIMITER字符。您在上面标识了制表符分隔符。- HAWQ群集的HDFS
SQL脚本
create_pxf_tables.sql为其余的Retail维度数据创建HAWQ外部表定义。在另一个终端窗口中,编辑create_pxf_tables.sql,将每次出现的NAMENODE替换为您在上一步中指定的主机名或IP地址。例如:gpadmin@master$ cd $HAWQGSBASE/tutorials/getstart/pxf gpadmin@master$ vi create_pxf_tables.sql运行
create_pxf_tables.sqlSQL脚本以创建其余的HAWQ外部表定义,然后退出psql子系统:hawqgsdb=# \i create_pxf_tables.sql hawqgsdb=# \q注意:
create_pxf_tables.sql脚本会在尝试创建每个外部表之前将其删除。如果这是您第一次执行此练习,则可以放心地忽略psql“table does not exist, skipping”消息。- 运行以下脚本,以验证您是否成功创建了外部表定义:
gpadmin@master$ ./verify_create_pxf_tables.sh脚本的输出应与以下内容匹配:
Table Name | Count -------------------------------+------------------------ customers_dim_pxf | 401430 categories_dim_pxf | 56 customer_addresses_dim_pxf | 1130639 email_addresses_dim_pxf | 401430 payment_methods_pxf | 5 products_dim_pxf | 698911 -------------------------------+------------------------ 通过在
payment_methods_pxf表上运行以下查询来显示允许的付款方式:gpadmin@master$ psql hawqgsdb=# SELECT * FROM retail_demo.payment_methods_pxf; payment_method_id | payment_method_code -------------------+--------------------- 4 | GiftCertificate 3 | CreditCard 5 | FreeReplacement 2 | Credit 1 | COD (5 rows)在
customers_dim_pxf和customer_addresses_dim_pxf表上运行以下查询,以显示邮政编码为06119的所有男性顾客的姓名:hawqgsdb=# SELECT last_name, first_name FROM retail_demo.customers_dim_pxf, retail_demo.customer_addresses_dim_pxf WHERE retail_demo.customers_dim_pxf.customer_id=retail_demo.customer_addresses_dim_pxf.customer_id AND retail_demo.customer_addresses_dim_pxf.zip_code='06119' AND retail_demo.customers_dim_pxf.gender='M';将您的输出与以下内容进行比较:
last_name | first_name -----------+------------ Gigliotti | Maurice Detweiler | Rashaad Nusbaum | Morton Mann | Damian ...- 退出psql子系统:
hawqgsdb=# \q
练习: 查询HAWQ和PXF表
通常,数据将同时驻留在HAWQ表和外部数据源中。
在这些情况下,可以同时使用HAWQ内部表和PXF外部表来关联和查询数据。
执行以下步骤,确定所有购买了礼券的客户的姓名和电子邮件地址,并提供此类购买的总体订单总额。
订单事实数据驻留在HAWQ管理的表中,而客户数据驻留在HDFS中。
启动psql子系统:
gpadmin@master$ psql hawqgsdb=#可通过上一课中创建的
orders_hawq表访问订单事实数据。可通过上一个练习中创建的customers_dim_pxf表访问customers数据。使用这些内部和外部HAWQ表,构造查询以识别所有购买了礼券的客户的姓名和电子邮件地址;还包括此类购买的总订单总额:hawqgsdb=# SELECT substring(retail_demo.orders_hawq.customer_email_address for 37) AS email_address, last_name, sum(retail_demo.orders_hawq.total_paid_amount::float8) AS gift_cert_total FROM retail_demo.customers_dim_pxf, retail_demo.orders_hawq WHERE retail_demo.orders_hawq.payment_method_code='GiftCertificate' AND retail_demo.orders_hawq.customer_id=retail_demo.customers_dim_pxf.customer_id GROUP BY retail_demo.orders_hawq.customer_email_address, last_name ORDER BY last_name;上面的
SELECT语句使用HAWQorders_hawq和PXF外部customer_dim_pxf表中的列来构成查询。将orders_hawqcustomer_id字段与customers_dim_pxfcustomer_id字段进行比较,以生成与特定客户关联的订单,其中orders_hawqpayment_method_code标识GiftCertificate。 查询输出:email_address | last_name | gift_cert_total ---------------------------------------+----------------+------------------- Christopher.Aaron@phpmydirectory.com | Aaron | 17.16 Libbie.Aaron@qatarw.com | Aaron | 102.33 Jay.Aaron@aljsad.net | Aaron | 72.36 Marybelle.Abad@idividi.com.mk | Abad | 14.97 Suellen.Abad@anatranny.com | Abad | 125.93 Luvenia.Abad@mediabiz.de | Abad | 107.99 ...随时输入
q退出查询结果。退出psql子系统:
hawqgsdb=# \q
概括
在本课程中,您创建了PXF外部表来访问HDFS数据并查询了这些表。
您还使用此外部数据和先前创建的HAWQ内部事实表执行了查询,并对托管和非托管数据都执行了业务逻辑。
有关PXF的其他信息,请参阅对非托管数据使用PXF。
有关PXF HDFS插件的详细信息,请参阅访问HDFS文件数据。
本课程总结了HAWQ入门教程。既然您已经熟悉了基本的环境设置,群集,数据库和数据管理活动,那么与HAWQ群集进行交互时应该会更加自信。
后续步骤:查看与运行HAWQ群集有关的HAWQ文档。
文档信息
- 本文作者:fei
- 本文链接:https://ayee1616166.github.io/2021/03/12/ApacheHAWQ_GettingStartedwithHAWQ_Tutorial_03/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)